Simplest lxml parsing example
Below is an xml document that is about as simple as one can get.
<?xml version="1.0" encoding="UTF-8"?>
<cat>
<name>Molly</name>
</cat>
Put that in a file called doc.xml.
Now how would you parse it with Python to get at the cat's name?
Use lxml, a Python xml parsing library.
The library is based on the API introduced by a prior library called ElementTree. It is now preferred over it, because lxml has extra features such as XPath queries.
import lxml.etree
tree = lxml.etree.parse('doc.xml')
cat_name = tree.xpath('/cat/name')[0].text
print cat_name # Molly
XPath is used above to define where the cat's name appears.
App Engine
To use lxml on Google App engine, put this in your app.yaml
libraries:
- name: lxml
version: "latest"
Then you can just do "import lxml" in your code.
If in GoogleAppEngineLauncher (dev_appserver.py) you get "ImportError: No module named lxml", do remember to install locally too ("sudo pip install lxml").
More to read
Python XML processing with lxml
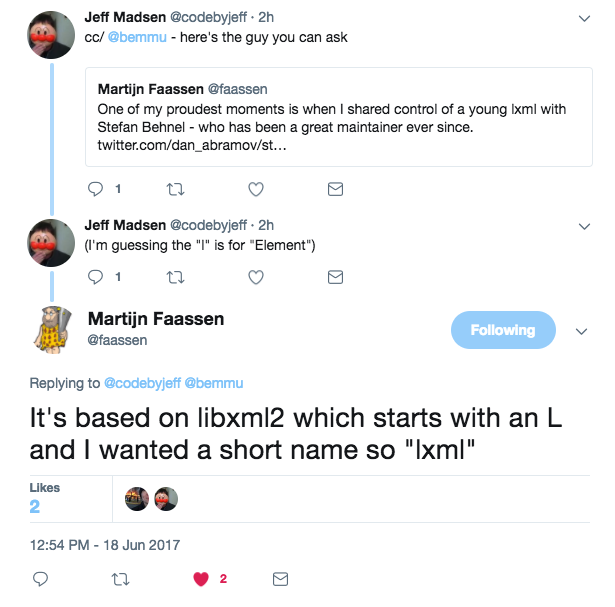
Bonus: origin of the lxml name
PS. I wanted to mention where the name "lxml" comes from here, but could not find the answer. If you know, let me know by email or @bemmu on Twitter.
Asking around on Twitter uncovered that the name "lxml" comes from it being based on libxml2, thanks codebyjeff and @faassen.